Exprimez vos émotions en regex !
Vous pensiez que nos émotions ne pouvaient pas être abordées de façon rationnelle ? Eh bien aujourd’hui nous allons tout de même essayer ! Je vous propose un petit voyage dans le monde merveilleux des regex et des emojis, ou en bon français, des expressions rationnelles et des émoticônes ; quoique ces dernières représentent en réalité un sous-ensemble d’emojis et plus généralement toute combinaison de caractères dédiée à l’expression d’émotions faciales ou gestuelles. Par commodité cependant, nous parlerons donc de regex et d’emojis.
Faisons le point
Avant tout, prenons le temps de nous rafraîchir la mémoire : Qu’est-ce qu’une regex, comment ça marche et à quoi ça sert ?
Une regex, nous dit Wikipedia, est :
[…] une chaîne de caractères, qui décrit, selon une syntaxe précise, un ensemble de chaînes de caractères possibles.
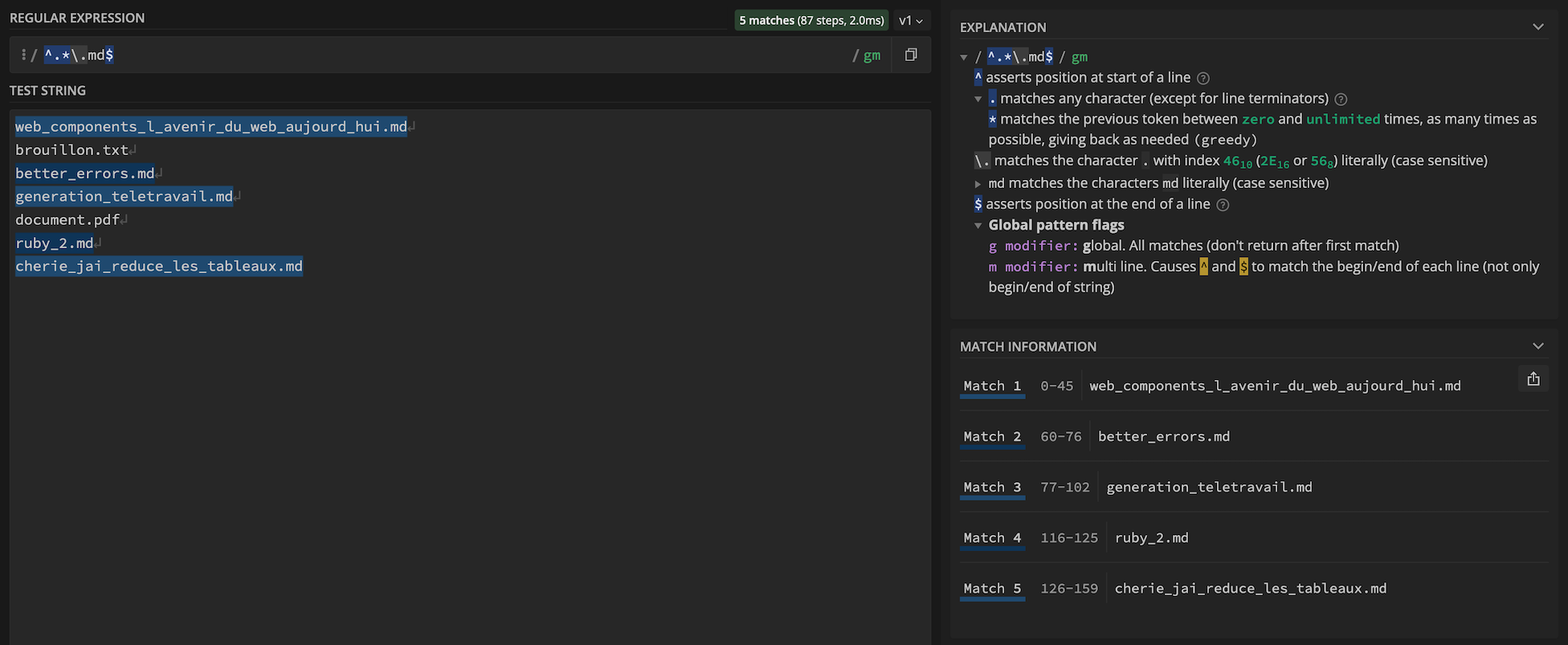
Prenons un exemple simple. Mettons que nous avons sous la main une liste de noms de fichiers et que nous souhaitons décrire l’ensemble « fichiers markdown » à l’aide d’une regex, nous pourrions utiliser celle-ci :
/^.*\.md$/gm
Si on la décortique, notre regex est délimitée par des slashs (/). Ce qui se
trouve après sont des options (g pour global, on recherche toutes les
occurrences ; m pour multiligne).
De nombreux caractères ont une signification bien précise au sein d’une regex.
Ici par exemple, on précise que l’on va rechercher du début (^) à la fin de la
ligne ($), n’importe quel caractère (.) un nombre indéterminé de fois (*)
allant de zéro à beaucoup. Puis, pour préciser qu’on requiert tout
spécifiquement le caractère point, on le préfixe d’un antislash (\.) afin
qu’il perde toute signification spéciale. Enfin on indique que notre chaîne de
caractère doit se terminer par md, qui est l’extension communément employée
pour un fichier Markdown.
C’est très abscons au début, on dirait des caractères jetés au hasard, mais je vous assure qu’on apprend très vite à lire cette syntaxe avec une fluidité déconcertante ;)
Voici notre exemple illustré à l’aide d’un outil en ligne fort pratique, regex101.
絵文字
Le saviez-vous ? Le mot emoji vient du japonais et signifie littéralement « image » (e 絵) + « lettre » (moji 文字) ; la ressemblance avec « émotion » est un jeu de mot interculturel.
L’art du camouflage
Un emoji peut en cacher un autre ! Selon vous, quel rapport y a-t-il entre les emojis suivants ?

Non, ils ne participent pas tous au Movember ! Par contre tous ces emojis sont dérivés du même, celui de gauche en l’occurrence. Réellement dérivés ! Je m’explique.
Unicode et emojis
Les emojis sont des caractères Unicode depuis la version 6.0 (octobre 2010) de la norme. On en dénombrait 722 à l’époque, ils sont plus de 2600 aujourd’hui !
Mais pour nombre d’entre eux, ce sont des séquences de caractères Unicode. Évidemment, il y a un certain formalisme à respecter et qui se définit comme ceci :
emoji_tag_sequence := tag_base tag_spec tag_term
tag_base := emoji_character
| emoji_modifier_sequence
| emoji_presentation_sequence
tag_spec := [\x{E0020}-\x{E007E}]+
tag_term := \x{E007F}
emoji_modifier_sequence :=
emoji_modifier_base emoji_modifier
Si on reprend nos bonshommes ci-dessus, notre base tag_base sera donc composée
de l’emoji 👨 (\u{1F468}), suivi d’une séquence de modification constituée
d’une base (ici le liant sans chasse
\u{200D}) et d’un emoji_modifier qui sera l’une des quatre coupes de cheveux
(de 🦰 \u{1F9B0} à 🦳 \u{1F9B3}]). Pas de tag_spec ici, on termine donc
notre séquence avec le cancel tag
\u{E007F}.
[1] pry(main)> "\u{1F468}"
=> "👨"
[2] pry(main)> "\u{1F468}\u{200D}\u{1F9B0}\u{E007F}"
=> "👨🦰️"
[3] pry(main)> "\u{1F468}\u{200D}\u{1F9B1}\u{E007F}"
=> "👨🦱️"
[4] pry(main)> "\u{1F468}\u{200D}\u{1F9B2}\u{E007F}"
=> "👨🦲️"
[5] pry(main)> "\u{1F468}\u{200D}\u{1F9B3}\u{E007F}"
=> "👨🦳️"
De la même manière, il est possible de modifier le teint de la peau.

Envie de briller en société ? Saviez-vous que les couleurs de peau des emojis ne sont pas choisies aléatoirement mais se basent sur la classification de Fitzpatrick qui permet de classer les individus selon la réaction de leur peau lors d’une exposition solaire ?
Et il est même possible de les combiner !
[1] pry(main)> "\u{1F468}\u{1F3FE}\u{200D}\u{1F9B3}\u{E007F}"
=> "👨🏾🦳️"
It’s raining men
On a vu que les emojis n’étaient rien d’autre que des caractères ou séquences de caractères Unicode. Il est donc possible de rechercher des emojis dans un texte à l’aide d’une regex, et qui plus est, sur la simple base d’un dénominateur commun !
Mais attendez une minute… est-ce vraiment faisable ? Ce sont tout de même des caractères assez particuliers, dont certains ne s’affichent même pas à l’écran ! Pas d’inquiétude ! Les regex sont vraiment très puissantes, nous allons voir ça ensemble.
Disons que nous disposons d’un texte bourré d’emojis et que nous souhaitons en extraire tous ceux qui correspondent à un bonhomme, peu importe sa coupe de cheveux ou sa couleur de peau. Voici notre texte de référence :
Codepoints
👨 U+1F468
Shortcodes
:man:
Related
👨 Man
👨🏻 Man: Light Skin Tone
👨🏼 Man: Medium-Light Skin Tone
👨🏽 Man: Medium Skin Tone
👨🏾 Man: Medium-Dark Skin Tone
👨🏿 Man: Dark Skin Tone
👩 Woman
👩🏻 Woman: Light Skin Tone
👩🏼 Woman: Medium-Light Skin Tone
👩🏽 Woman: Medium Skin Tone
👩🏾 Woman: Medium-Dark Skin Tone
👩🏿 Woman: Dark Skin Tone
See also
🧔 Man: Beard
🧔🏻 Man: Light Skin Tone, Beard
🧔🏼 Man: Medium-Light Skin Tone, Beard
🧔🏽 Man: Medium Skin Tone, Beard
🧔🏾 Man: Medium-Dark Skin Tone, Beard
🧔🏿 Man: Dark Skin Tone, Beard
👨🦳 Man: White Hair
👨🏻🦳 Man: Light Skin Tone, White Hair
👨🏼🦳 Man: Medium-Light Skin Tone, White Hair
👨🏽🦳 Man: Medium Skin Tone, White Hair
👨🏾🦳 Man: Medium-Dark Skin Tone, White Hair
👨🏿🦳 Man: Dark Skin Tone, White Hair
👩🦳 Woman: White Hair
👩🏻🦳 Woman: Light Skin Tone, White Hair
👩🏼🦳 Woman: Medium-Light Skin Tone, White Hair
👩🏽🦳 Woman: Medium Skin Tone, White Hair
👩🏾🦳 Woman: Medium-Dark Skin Tone, White Hair
👩🏿🦳 Woman: Dark Skin Tone, White Hair
👨🦰 Man: Red Hair
👨🏻🦰 Man: Light Skin Tone, Red Hair
👨🏼🦰 Man: Medium-Light Skin Tone, Red Hair
👨🏽🦰 Man: Medium Skin Tone, Red Hair
👨🏾🦰 Man: Medium-Dark Skin Tone, Red Hair
👨🏿🦰 Man: Dark Skin Tone, Red Hair
👩🦰 Woman: Red Hair
👩🏻🦰 Woman: Light Skin Tone, Red Hair
👩🏼🦰 Woman: Medium-Light Skin Tone, Red Hair
👩🏽🦰 Woman: Medium Skin Tone, Red Hair
👩🏾🦰 Woman: Medium-Dark Skin Tone, Red Hair
👩🏿🦰 Woman: Dark Skin Tone, Red Hair
👦 Boy
♂ Male Sign
🕺 Man Dancing
👲 Man With Chinese Cap
🕴 Man in Suit Levitating
🤵 Man in Tuxedo
👴 Old Man
👵 Old Woman
🎅 Santa Claus
Et maintenant, notre regex :
/(\x{1F468})(?:([\x{1F3FB}-\x{1F3FF}])?(\x{200D}[\x{1F9B0}-\x{1F9B3}])?\x{E007F}?)?/gm
Aïe ! Ça pique. Nous aurions tout aussi bien pu l’écrire comme ceci :
/(👨)(?:([🏻🏼🏽🏾🏿])?(\x{200D}[🦰🦱🦳🦲])?\x{E007F}?)?/gm
C’est déjà mieux, mais je vous l’accorde, ça mérite une petite explication. Décortiquons-la ensemble.
Plusieurs notions font leur apparition ici. Des groupes tout d’abord, au nombre de 3. C’est ce qui va nous permettre de récupérer des sous-ensembles pour chaque concordance (ou match).
Le premier groupe ne contient que notre caractère de base : (👨). Le second
groupe correspond à la couleur de peau ([🏻🏼🏽🏾🏿])? qui peut ou non être
présente, c’est la signification du quantificateur ?. Et notre troisième
groupe se trouve être la séquence de modification relative à la coupe de cheveux
(\x{200D}[🦰🦱🦳🦲])? à la suite de laquelle on retrouve le délimiteur de fin
de séquence \x{E007F}.
Vous remarquerez qu’il nous est possible de mentionner n’importe quel caractère
Unicode à l’aide de sa représentation hexadécimal que l’on nomme codepoint. À
noter qu’en Ruby on utilisera la syntaxe \u{ }, mais que plus communément
dans d’autres langages, comme Perl ou Go pour ne citer qu’eux, on préfèrera
\x{ }.
Une autre bizarrerie s’est immiscée dans notre regex, il s’agit d’un groupe
non capturant. Sa syntaxe est (?: ). Son principal intérêt est de pouvoir
préciser un quantificateur sur un groupe de caractères, sans pour autant
retrouver ce groupe dans le résultat final. Ici, il nous permet d’indiquer que
nous recherchons le caractère de base 👨 suivi ou non de modificateurs.
Dans l’exemple ci-dessus, nous avons 19 concordances. En voici un extrait :
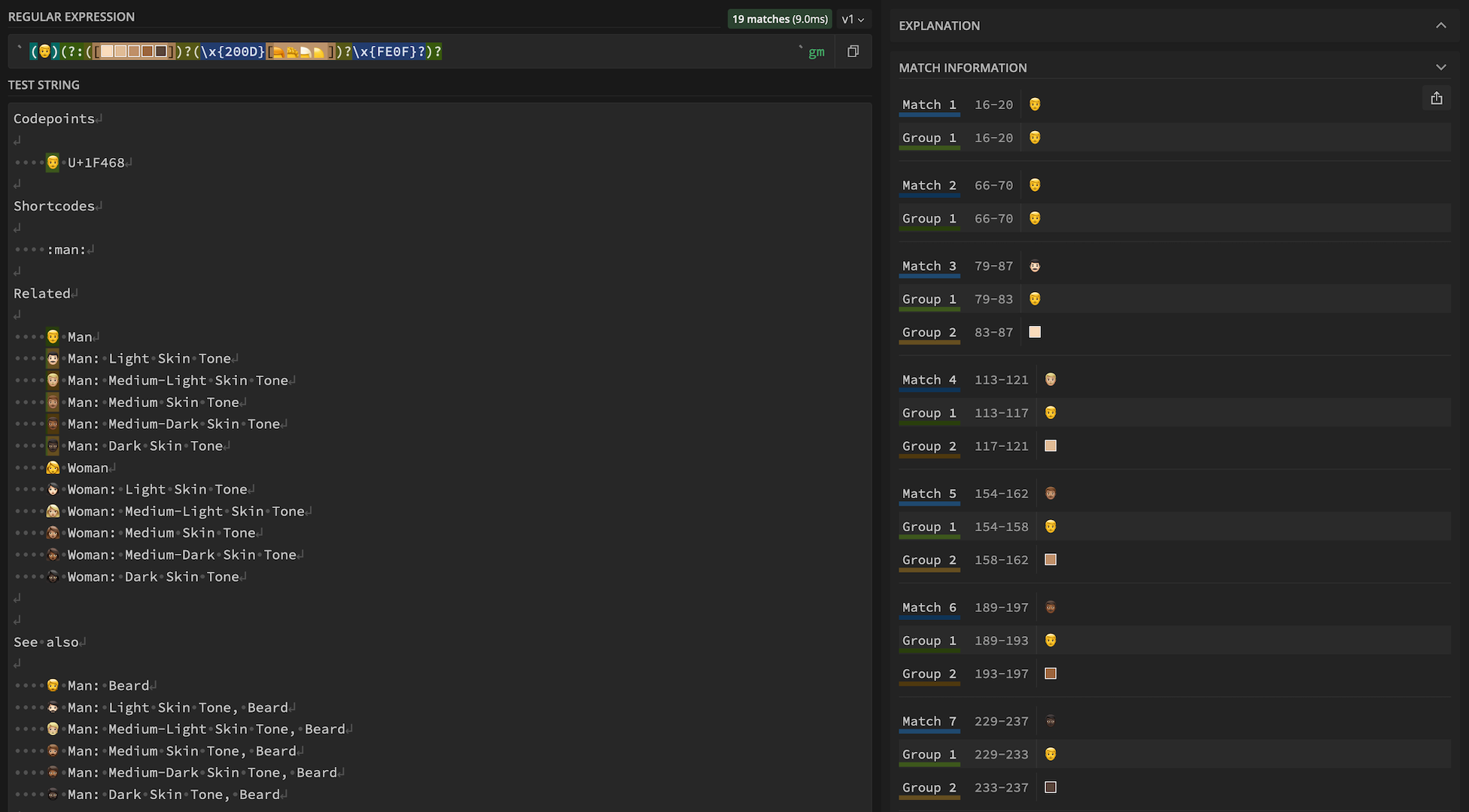
Pour voir l’intégralité des concordances, jouer avec notre regex et en comprendre la composition dans le détail, rendez-vous sur regex101 ;)
Fun with flags

Unicode inclut aussi un ensemble d’emojis représentant plus de 200 drapeaux !
Astuce du jour : la prochaine fois que vous jouerez au Scrabble, essayez de placer vexillologie, il s’agit du nom donné à l’étude des drapeaux et pavillons :)
Ces emojis sont eux aussi le résultat de séquences de caractères qui répondent au format suivant :
emoji_flag_sequence :=
regional_indicator regional_indicator
regional_indicator := \p{Regional_Indicator}
Voyez-vous ça ! Mais quelle est donc cette syntaxe \p{ } ? Il s’agit là
d’une référence à une classe de caractères. Cette même syntaxe peut être
utilisée au sein d’une regex pour adresser un ensemble prédéfini de caractères.
Prenons un exemple. Supposons que nous souhaitions extraire tous les symboles monétaires d’un texte. Et il en existe une ribambelle ! Voici comment nous pourrions nous y prendre :
/\p{Sc}/g
Ce qui, pour le texte qui suit, nous retournerait 4 occurrences :
Vous pouvez payer en
€uro en£ivre ou en¥en. Et même en₿itcoin !
Des classes de caractères, il en existe des dizaines. Mais ne nous égarons pas, cela pourra faire l’objet d’un autre article.
Indicateurs régionaux
Les indicateurs régionaux, sont en réalité un ensemble de 26 caractères alphabétiques cerclés de pointillés. Les emojis représentant des drapeaux de pays sont donc constitués de deux de ces caractères, conformément à la norme ISO 3366-1.
[1] pry(main)> "\u{1F1EB}\u{1F1F7}"
=> "🇫🇷"
[2] pry(main)> "\u{1F1EB} \u{1F1F7}"
=> "🇫 🇷"
[3] pry(main)> "\u{1F1EC}\u{1F1E7}"
=> "🇬🇧"
[4] pry(main)> "\u{1F1EC} \u{1F1E7}"
=> "🇬 🇧"
Ainsi, admettons que nous ayons à notre disposition un ensemble de drapeaux et que nous aimerions distinguer les drapeaux de pays des autres types de drapeaux à l’aide d’une regex, il nous suffirait de nous y prendre comme ceci :
[\x{1F1E6}-\x{1F1FF}]{2}
Que l’on peut aussi écrire :
[🇦-🇿]{2}
Notez que Ruby est particulièrement bon dans la gestion d’Unicode, car nombre de langages ne supportent pas l’utilisation d’intervalle pour ce type de caractères.
L’occasion pour moi de vous présenter Rubular, un autre outil en ligne, cette fois dédié à l’édition de regex pour Ruby spécifiquement. La regex présentée ci-dessus est éprouvée ici sur l’extrait de code Ruby qui la précède.
Si on y prête attention, certains drapeaux semblent néanmoins passer entre les mailles du filet !
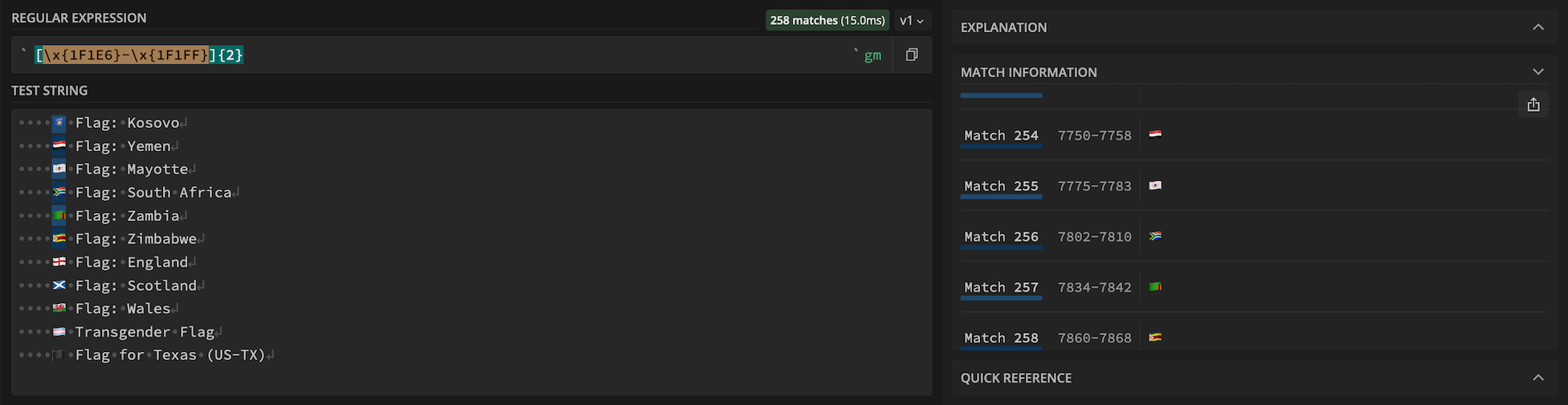
Si l’on fait fit du drapeau transgenre qui n’est supporté que par quelques réseaux sociaux et n’est de toute façon pas un drapeau de pays, celui de l’État américain du Texas, ou encore ceux de l’Angleterre, de l’Écosse et du Pays de Galles sont exclus de notre résultat. En réalité, il ne s’agit pas de pays au sens strict. Ceux-ci sont décrits par une séquence de 2+2 ou 2+3 indicateurs régionaux, représentant le pays suivi d’une subdivision régionale.
[1] pry(main)> Emoji::Character.hex_inspect("🏴")
=> "1f3f4-e0067-e0062-e0065-e006e-e0067-e007f"
[2] pry(main)> Emoji::Character.hex_inspect("🏴")
=> "1f3f4-e0067-e0062-e0077-e006c-e0073-e007f"
[3] pry(main)> Emoji::Character.hex_inspect("🏴")
=> "1f3f4-e0067-e0062-e0073-e0063-e0074-e007f"
J’utilise ici une gem Ruby fort pratique nommée gemoji afin de décomposer un emoji en codepoints. En décomposant le drapeau de l’Angleterre, on obtient ceci :
[140] pry(main)> "\u{1F3F4} \u{E0067} \u{E0062} \u{E0065} \u{E006E} \u{E0067} \u{E007F}"
=> "🏴 "
En y regardant de plus près, on s’aperçoit que cet emoji contient un ensemble de
codepoints que l’on n’a pas encore rencontré, encadrés d’un drapeau noir 🏴 et
du fameux caractère de fin de séquence \u{E007F}. Ces codepoints font partie
de la classe de caractères tags et
sont réservés à des usages divers. Ceux utilisés ici pour l’Angleterre
symbolisent les lettres gbeng. Sans surprise, ce sera gbwls pour le Pays de
Galles et gbsct pour l’Écosse.
Si l’on souhaitait retravailler notre précédente regex pour prendre en compte
les drapeaux représentant des subdivisions régionales, nous n’aurions d’autre
choix que de tester l’un ou l’autre cas,
les deux types de séquences étant entièrement différentes ! Pour ce faire, on
utilise la syntaxe a|b, à la manière d’un « ou logique » entre deux
propositions.
/[\x{1F1E6}-\x{1F1FF}]{2}|🏴[\x{E0041}-\x{E007A}]{4,5}\x{E007F}/
Cette regex est l’occasion de vous présenter une dernière petite chose. Il est
possible, comme c’est le cas ici, d’utiliser un quantificateur indiquant un
nombre précis d’occurrences attendues. Dans la regex ci-dessus, on attend très
exactement 4 à 5 tags ; cela s’écrit {4,5} à la suite du ou des caractères
concernés.
So long and thanks for all the fish 👋🙏🐟
Avant de se quitter, voici quelques ressources qui vous permettront de creuser le sujet si le cœur vous en dit.
Pour commencer, en cas de doute (ou d’insomnie) jetez un œil à la référence ultime : Unicode® Technical Standard #51. Puis pour se faire une idée de l’étendue des caractères que propose Unicode, rien de tel que Unicode Table. Enfin, pour rechercher un emoji et en connaître sa composition, allez faire un tour sur Emojipedia.
Et si vous êtes anglophone, deux excellents articles : le premier sur l’optimisation de regex manipulant des emojis « Optimizing regex for emoji » et le second portant sur Ruby et Unicode « Ruby has Character ».