Rails n'est pas simple !
Considérons ceci :
User.create(params[:user])
La ligne de code ci-dessus n’est pas simple. Elle est facile à écrire, mais il réside une grande complexité dans le code qui se cache derrière :
- les paramètres devront souvent passer par des coercions spécifiques à la base de données ;
- les paramètres devront être validés ;
- les paramètres peuvent être modifiés par des callbacks, pouvant occasionnellement causer des effets de bords ;
- des paramètres invalides conduisent à la génération de messages d’erreur qui dépendent d’une externalité (ex: I18n) ;
- des paramètres valides découlera l’instanciation d’un objet, potentiellement accompagnée d’autres objets associés ;
- un objet, voire tout une grappe d’objets seront stockés en base de données.
Tel est le constat fait par Piotr Solnica (a.k.a Solnic) sur son blog dans un billet de 2016.
Résumons-nous et évitons toute confusion entre « simple » et « facile » :
Simple : une ligne de code qui fait une seule petite chose très spécifique.
Facile : une ligne de code qui en fait beaucoup en faisant appel à une méthode du framework et résultant en l’exécution d’un millier de lignes de code.
Ruby on Rails a été pensé pour être facile à utiliser. Ce qui est très pratique pour un POC ou un petit projet. Mais cela manque clairement de séparation des responsabilités — comme on a pu le constater avec l’exemple ci-dessus —, ce qui est dommageable quand le projet commence à grossir, car en créant du couplage, le code devient alors plus difficile à maintenir, à tester et à faire évoluer.
Repenser son architecture
Une bonne architecture de projet sera votre meilleure alliée aussi longtemps que vivra et évoluera votre application. Notre précédent article sur DRY (don’t repeat yourself) ne vous aura pas échappé. Il s’agit ici d’appliquer ce principe à l’échelle non plus d’un projet, mais d’une équipe. Partager des conventions d’architecture à l’échelle d’une équipe, entre vos différents projets, est d’autant plus bénéfique que cela en facilitera la prise en main tout en assurant à votre projet une maintenabilité, une évolutivité et une testabilité accrues.
Rails propose en standard une architecture dite MVC. Celle-ci s’avère aisée à prendre en main, pour autant, elle montre très rapidement ses limites dès que le projet commence à s’étoffer.
As everything with Rails, it was “nice and easy in the beginning” and then it would turn into unmaintainable crap.
— Piotr Solnica, 2016
Ce que je vous propose ici, c’est d’affiner cette architecture en lui apportant quelques notions librement inspirées d’autres écoles de pensée. Pour bien comprendre vers quoi je veux vous mener, rien de tel qu’un petit schéma !
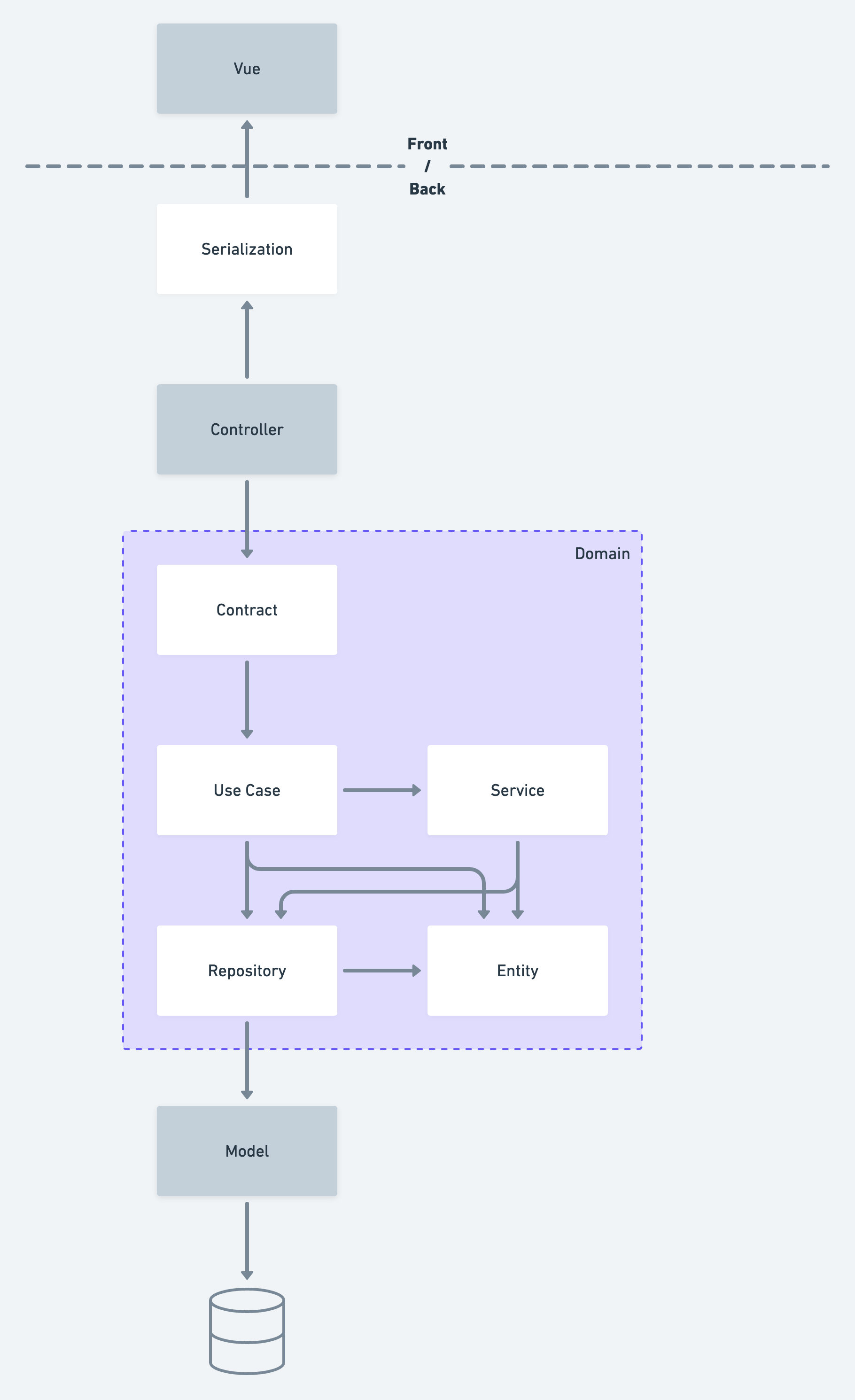
Comme vous pouvez le constater, cela consiste principalement en un découpage plus fin des responsabilités entre les couches modèle (model) et contrôleur (controller).
Le saviez-vous ? L’architecture MVC a été élaborée dans les années 1970 par Trygve Reenskaug pour Smalltalk-79 et ne s’appliquait non pas à un écran entier, mais à chacun de ses composants ! Chaque bouton, chaque input avait son modèle, sa vue et son contrôleur qui lui étaient propres. (source : Wikipédia)
Détaillons ensemble ces différentes notions, en commençant par la plus structurante mais trop souvent oubliée : les domaines.
Domaines
Dans une conférence donnée par Robert Martin (a.k.a Uncle Bob) à Ruby Midwest en 2011, il posait la question suivante après avoir jeté un œil à l’arborescence d’un projet :
Hmm… it looks like a Rails app. Why should the top level directory structure communicate that information to you? What does this application do?
— Robert Martin, 2011
Et de poursuivre :
The most visible level, the level that everybody goes to first: nothing here talks about what this application does! […] So apparently, the most important thing about this application is the framework upon which it is built.
— Robert Martin, 2011
Or, lorsqu’on regarde un plan dessiné par un architecte qu’y voit-on ? Une grande entrée, de nombreuses étagères, des tables au centre… on dirait bien une bibliothèque ! Le premier niveau de lecture nous informe tout de suite qu’il s’agit d’une bibliothèque, et non pas d’une construction en béton. D’un seul coup d’œil, on comprend à quel besoin répond ce bâtiment.
Ainsi, les domaines (domains) servent à délimiter les différents aspects métiers de l’application. Ils définissent l’arborescence de notre projet pour tout ce qui a trait à la modélisation du besoin exprimé par le Métier.
Note : ce que je nomme ici le Métier — avec une majuscule — ce sont les interlocuteurs qui ensemble ont une connaissance fine du besoin que tente d’adresser l’application.
app/domain/
├── customer/
│ ├── contracts/
│ ├── entities/
│ ├── repositories/
│ ├── services/
│ └── use_cases/
└── security/
├── entities/
├── repositories/
└── use_cases/
Contrats
L’entrée au sein d’un domaine se fait dans le respect d’un contrat (contract). Celui-ci établit la nature des données attendues en entrée par le cas d’usage (use case) que l’on souhaite adresser. Si le contrat n’est pas respecté, une erreur détaillant les raisons du refus sera immédiatement retournée au contrôleur (controller), sans poursuivre plus avant.
module Customer
module Contracts
class ListEmails < MyApp::ApplicationContract
params do
required(:page).hash do
required(:number).value(:integer, gt?: 0)
required(:size).value(:integer, gt?: 0)
end
optional(:filter).hash do
optional(:subject).filled(:string)
optional(:recipient).filled(:string)
end
end
rule(:recipient) do
key.failure("has invalid format") unless /@/.match?(value)
end
end
end
end
Ainsi, les contrats agissent comme des sas de décontamination : tout ce qui respecte ledit contrat est de fait considéré comme digne de confiance. Dès lors, le code métier est épuré de tout code défensif, devenu inutile au-delà de ce sas.
Cas d’Usage
Le contrat respecté, les données sont transmises au cas d’usage (use case)
afin de procéder à son exécution. Un cas d’usage représente un scénario
élémentaire, par exemple, « lister les adresses d’un client » ou « ajouter un
produit au panier ». Un cas d’usage pourra ainsi faire appel à un service
(service), à des répertoires (repositories), et manipulera des entités
(entities) qui seront retournées encapsulées dans une structure
Result::Success en cas de succès. Dans le cas contraire, une structure
Result::Failure sera retournée, précisant la raison de l’échec. Le résultat
ainsi structuré de l’exécution du cas d’usage nous garantit un traitement
facilité de celui-ci par le contrôleur.
module Customer
module UseCases
class GetEmail
include Dry::Monads[:result, :do]
include Dry::Matcher::ResultMatcher.for(:call)
include MyApp::Deps[sent_emails_repo: "customer.repositories.sent_emails",
contract: "customer.contracts.get_email"]
def call(params = {})
validate(params).bind do |params|
email_uid = params[:uid]
email = sent_emails_repo.get_by_uid(uid)
if email
Success(email)
else
Failure([:resource_not_found, "Email with uid #{uid} not found"])
end
end
end
private
def validate(params)
validation = contract.call(params)
if validation.success?
Success(validation.to_h)
else
Failure([:validation_error, validation.errors.to_h]
end
end
end
end
end
Sans nous attarder sur l’implémentation technique qu’on abordera en seconde partie d’article, remarquons que l’on retrouve ici quelques notions déjà évoquées dans d’autres articles sur le blog de Synbioz, telles que l’injection de dépendance, le pattern matching ou encore le découplage, fil rouge de ce billet.
Services
Un service (service) ressemble peu ou prou à un cas d’usage, à ceci près qu’il n’est pas appelé par un contrôleur mais par un cas d’usage ou un autre service. On se trouve au sein du domaine, en zone de confiance, nous avons pleine maîtrise des données d’entrée du service : ainsi, nul besoin de les garantir par un contrat.
module Customer
module Services
class SendEmail
include Dry::Monads[:result]
include MyApp::Deps[sent_emails_repo: "customer.repositories.sent_emails"]
def call(email)
SimpleMailer.with(
recipients: email.recipients,
subject: email.subject,
body: email.body
).email.deliver_now
email = sent_emails_repo.persist!(email)
Success(email)
end
end
end
end
Besoin de faire appel à un système externe ? De générer un code répondant à des contraintes du Métier ? D’implémenter un comportement qui peut être mutualisé ? Pensez à isoler cela dans un service ! Pour faire écho à l’article duplication ou coïncidence, chaque besoin exprimé par le Métier devra trouver corps dans une implémentation unique et non ambiguë, faisant autorité à travers toute l’application.
Répertoires
Les répertoires (repositories) sont une passerelle entre la représentation métier des données — les entités — et leur persistance. Seuls les répertoires ont la responsabilité de construire une entité, de la persister, de l’effacer… bref. Contrairement à un projet Rails classique, la structure de la base de données n’impacte pas la modélisation des entités que l’on manipule.
module Customer
module Repositories
class SentEmails
def persist!(email)
record = Email.create!(
uid: email.uid,
body: email.body,
subject: email.subject,
workflow: workflow,
recipients: email.recipients,
sent: true
)
Mapper.from_record(record)
end
private
class Mapper
def self.from_record(record)
Customer::Entities::SentEmail.new(
internal_id: record.id,
uid: record.uid,
body: record.body,
subject: record.subject,
recipients: record.recipients
)
end
end
end
end
end
De plus, tout en présentant une interface similaire à celle des autres répertoires, il se peut qu’un répertoire interroge en toute transparence une API, un fichier, ou la mémoire, plutôt que la base de données de l’application.
module Customer
module Repositories
class InMemorySentEmails
def initialize
@store = {}
end
def persist!(email)
record = @store[email.uid] = {
uid: email.uid,
body: email.body,
subject: email.subject,
recipients: email.recipients,
sent: true
}
Mapper.from_record(record)
end
class Mapper
def self.from_record(record)
Customer::Entities::SentEmail.new(
uid: record.uid,
body: record.body,
subject: record.subject,
recipients: record.recipients
)
end
end
end
end
end
Tout bien considérée, la base de données n’est qu’un détail. Ce n’est pas le cœur du besoin exprimé, juste une incidence technique. Réduire le couplage avec celle-ci nous permet de nous en abstraire, voire d’en changer, aisément.
Entités
Comme énoncé ci-dessus, une entité (entity) est la représentation, au sein d’un domaine et du point de vue du Métier, d’une brique élémentaire de l’application. Elle représente quelque chose que le Métier peut toucher du doigt et doit de préférence répondre à une nomenclature définie avec celui-ci.
module Customer
module Entities
class SentEmail
def initialize(**kwargs)
attrs = kwargs.symbolize_keys
@internal_id = attrs[:internal_id]
@uid = attrs[:uid]
@body = attrs[:body]
@subject = attrs[:subject]
@recipients = attrs[:recipients]
end
attr_reader :internal_id, :uid, :body, :recipients, :subject
def sent?
true
end
end
end
end
Ainsi, et en totale indépendance du mode de persistance choisi, les entités nous servent à manipuler les notions et concepts nécessaires pour répondre au besoin exprimé par le Métier. Il est entendu que chaque entité est contenue et se limite à un domaine précis. Ce faisant, pour reprendre un exemple classique, un produit dans un catalogue et ce même produit dans une ligne de facturation se modéliseront différemment selon leur domaine respectif, ne présentant que ce qu’il y a de pertinent dans le contexte dans lequel ces entités seront employées.
Modèles
Les modèles (models) ActiveRecord sont réduits à leur strict minimum. Aucun
code métier puisqu’on est ici en dehors d’un domaine. Il s’agit simplement d’une
modélisation de la structure de la base de données de l’application. On peut à
la rigueur y trouver quelques scopes pour aider au requêtage au sein des
répertoires, ou la déclaration d’un enum. Mais dans la majorité des cas, on se
contentera de déclarer une classe héritant d’ApplicationRecord, la magie de
Rails et d’ActiveRecord opèrera.
class Email < ApplicationRecord
end
Contrôleurs
Les contrôleurs (controllers) ont eux aussi un rôle limité. Ils servent à
l’aiguillage. Un contrôleur appel un cas d’usage et en fonction du retour de ce
dernier (Result::Success ou Result::Failure), fera tel ou tel rendu, avec ou
sans message d’erreur selon le cas. Les données retournées par le contrôleur
seront préalablement sérialisées afin de correspondre aux attentes de la vue ou
du consommateur de l’API.
class EmailsController < ApplicationController
def template
resolve("customer.use_cases.get_email_template").call(params.to_h) do |m|
m.success do |email|
render json: EmailSerializer.new(email).as_json
end
m.failure do |error|
handle_error(error)
end
end
end
end
Sérialisation
La sérialisation permet l’interface entre les données servies au contrôleur par le domaine et la structure de données que l’on souhaite présenter au consommateur de l’API ou à la vue.
class EmailSerializer
def initialize(email)
@email = email
end
def as_json
{
body: @email.body,
subject: @email.subject,
recipients: @email.recipients
}
end
end
On peut, si on le souhaite, distinguer sérialisation (serializer) et présentation (presenter) selon que l’on cible respectivement un consommateur d’API ou une vue.
En vérité, vous êtes libres de vous doter des outils et concepts qui œuvreront à clarifier votre base de code, vous aide à la maintenir et à la faire évoluer sans peine. La clé d’une architecture réussie réside dans une approche incrémentale et inclusive : évitez à tout prix de vouloir mettre en place trop de concepts mal maitrisés. Dosez. Et accompagnez les membres de l’équipe et nouveaux arrivants de manière à ce que chacun s’approprie les outils à sa disposition.
Avantages
Différer les décisions
A good architecture maximizes the number of decisions NOT made.
— Uncle Bob
L’architecture proposée ici nous permet de concentrer nos efforts sur le besoin exprimé plutôt que sur des choix techniques. Doit-on utiliser une base de données relationnelle ou noSQL ? Plutôt PostgreSQL ou MySQL ? Peu importe, la base de données est un détail, isolez-la !, nous dit Uncle Bob. Commençons par exemple par une persistance en mémoire et nous aviserons ensuite, à mesure que les contraintes techniques se précisent. En effet, grâce à la présence de répertoires qui font l’interface entre les entités et leur persistance, il est très facile d’en substituer un par un autre.
En fait, chacune des notions ici présentées a des responsabilités très limitées et participe de la réduction du couplage dans notre application. Il est dès lors très simple de remplacer, d’altérer, de simuler le comportement de l’un des composants de cette architecture.
Test
Voici le résultat de l’exécution d’un projet Rails architecturé selon les principes évoqués ici-même.
Finished in 4.997038s, 105.8627 runs/s, 173.3027 assertions/s.
529 runs, 866 assertions, 0 failures, 0 errors, 0 skips
Quelques secondes pour l’ensemble de la suite de tests. Et toutes les couches sont testées : tests de bout à bout (end to end), tests unitaires, appels en base de données, rien n’est épargné.
La raison de cette vélocité ? La majorité des objets manipulés sont de simples
classes Ruby (PORO, Pure Old Ruby Object) sans aucune dépendance à
ActiveRecord ou autre ActiveMachin.
L’autre raison, c’est qu’en testant chacune des couches, on peut s’autoriser à en simuler (stub) les dépendances. Ainsi, lorsqu’on teste un cas d’usage, on ne teste pas de nouveau les services dont il dépend — déjà testés en isolation par ailleurs —, on ne passe pas non plus par la couche de persistance : les répertoires seront simulés eux aussi.
Un bon outillage
Une bonne architecture, surtout si on souhaite capitaliser dessus à l’échelle d’une équipe et à travers plusieurs projets, repose sur de bons outils. Des outils éprouvés et pensés dans le respect des principes SOLID, favorisant un faible couplage et une responsabilité limitée.
De tels outils existent dans l’écosystème Ruby depuis quelques années, je pense notamment aux gems dry-rb que l’on retrouve notamment dans les projets Ruby Object Mapper (a.k.a rom-rb), Hanami ou encore Trailblazer.
Découvrons ensemble trois d’entre elles : dry-validation, dry-types et
dry-system que vous avez pu entrevoir dans les extraits de code en première
partie d’article.
DRY Validation
Il s’agit là de la gem utilisée par nos contrats. dry-validation a vu le jour en 2015 et repose sur des contrats sans état qu’il nous appartient de définir.
Nous avons donc ici un découplage entre un modèle — qu’il s’agisse d’un modèle
ActiveRecord ou d’une entité — et sa validation. On s’évite ainsi de potentiels
conflits de méthodes (notre modèle peut tout à fait posséder un attribut
errors par exemple). De plus, dry-validation supporte la validation de
structures de données complexes et permet la distinction entre les règles
métier et le contrôle purement technique des types de données.
class ListEmails < Ant::ApplicationContract
params do
required(:page).hash do
required(:number).value(:integer, gt?: 0)
required(:size).value(:integer, gt?: 0)
end
optional(:filter).hash do
optional(:subject).filled(:string)
optional(:recipient).filled(:string)
end
end
rule(filter: :recipient) do
key.failure("has invalid format") unless /@/.match?(value)
end
end
contract = ListEmails.new
params = {
page: { number: 1, size: 25 },
filter: { recipient: "jane@doe.org" }
}
contract.call(params)
# => #<Dry::Validation::Result{:page=>{:number=>1, :size=>25}, :filter=>{:recipient=>"jane@doe.org"}} errors={}>
params = {
filter: { recipient: "jane.doe.org" }
}
contract.call(params)
# => #<Dry::Validation::Result{:filter=>{:recipient=>"jane.doe.org"}} errors={:page=>["is missing"], :filter=>{:recipient=>["has invalid format"]}}>
DRY Types & DRY Struct
Cette gem apparue en 2016 est dans la lignée de DataMapper ou Virtus que certains parmi vous connaissent peut-être un peu mieux.
dry-types peut être utilisée conjointement
avec dry-validation et permet de créer des types de données très simplement,
d’en définir les contraintes, d’en personnaliser le constructeur, et même de les
composer pour en créer de nouveaux (ex: Types::Integer | Types::String).
module Types
include Dry.Types()
IsoCode = Types::String.constrained(format: /\A([A-Z]{2})\z/)
ParsedDate = Types::Date.constructor { |value| ::DateTime.parse(value) }
end
Types::IsoCode["FRA"]
# Dry::Types::ConstraintError: "FRA" violates constraints (format?(/\A([A-Z]{2})\z/, "FRA") failed)
Types::IsoCode["FR"]
# => "FR"
Types::ParsedDate["2020-10-01T07:43:31+00:00"]
# => Thu, 01 Oct 2020 07:43:31 +0000
Types::ParsedDate["today"]
# Dry::Types::CoercionError: invalid date
DRY System
Créée en 2015, cette gem se veut être un orchestrateur pour les dépendances de votre projet, évitant ainsi l’injection de dépendance manuelle à travers chaque brique applicative. Chaque dépendance est ainsi prête à l’emploi, disponible via un objet nommé container, sans avoir à se soucier à chaque utilisation de l’importer, de comment la configurer ou comment l’instancier.
L’objectif recherché est la consistance de l’application ainsi architecturée et la réduction de sa complexité. Cette gem est notamment utilisée par Hanami, framework web concurrent de Rails.
Si vous souhaitez utiliser dry-system avec Rails, il est recommandé d’utiliser dry-rails qui met en place un conteneur d’application pour vous et offre des fonctionnalités supplémentaires par-dessus.
Pour aller plus loin
Pour reprendre la main sur votre architecture logicielle et être en mesure de garantir une longue et belle vie à votre application et aux développeurs qui la chouchouteront, il y a quelques principes à garder en tête en permanence. Chaque décision peut être structurante, c’est pourquoi il est important de se demander si l’on ne se répète pas ? Si l’on n’est pas en train de créer du couplage ? Si l’on ne peut pas reporter cette décision à plus tard, quand on aura plus de contexte ? Si l’on ne prend pas la voie de la facilité au détriment de la simplicité ? Ne fabriquons pas les chaînes que nous aurons à porter plus tard !
Et pour les plus radicaux d’entre vous, demandez-vous ceci : dans les limites des domaines de mon application, puis-je facilement m’abstraire d’ActiveSupport ? Quel serait le coût d’une montée de version du framework ? Puis-je imaginer remplacer ActiveRecord par Ruby Object Mapper ? Allez, soyons fous : suis-je capable de m’abstraire totalement du framework ? De faire de Rails un détail d’implémentation que je pourrais remplacer par, disons, Hanami au hasard ? 🙃
L’écosystème Ruby est riche aujourd’hui de nombreux outils qui ne demandent qu’à être découverts ! Essayez, expérimentez, apprenez, ouvrez-vous à d’autres horizons, d’autres approches, d’autres pratiques. Aiguisez votre esprit critique, confrontez-les à vos pratiques actuelles, vous en ressortirez grandis !
Resources
- Piotr Solnica Blog
- Ruby Midwest 2011 - Architecture the Lost Years by Robert Martin
- Software Art Thou: Glenn Vanderburg - Real Software Engineering
- Le Domain Driven Design sous l’angle stratégique, une introduction